

Note: This article has been excerpted from my upcoming book, Learn F# . Save 37% off with code fccabraham!
Welcome to the world of data! This article will:
- Gently introduce us to what type providers are
- Get us up to speed with the most popular type provider, FSharp.Data.
What Are Type Providers?
Type Providers are a language feature first introduced in F#3.0:
An F# type provider is a component that provides types, properties, and methods for use in your program. Type providers are a significant part of F# 3.0 support for information-rich programming.
https://docs.microsoft.com/en-us/dotnet/articles/fsharp/tutorials/type-providers/index
At first glance, this sounds a bit fluffy – we already know what types, properties and methods are. And what does “information-rich programming” mean? Well, the short answer is to think of Type Providers as T4 Templates on steroids – that is, a form of code generation, but one that lives inside the F# compiler. Confused? Read on.
Understanding Type Providers
Let’s look at a somewhat holistic view of type providers first, before diving in and working with one to actually see what the fuss is all about. You’re already familiar with the notion of a compiler that parses C# (or F#) code and builds MSIL from which we can run applications, and if you’ve ever used Entity Framework (particularly the earlier versions) – or old-school SOAP web services in Visual Studio – you’ll be familiar with the idea of code generation tools such as T4 Templates or the like. These are tools which can generate C# code from another language or data source.

Ultimately, T4 Templates and the like, whilst useful, are somewhat awkward to use. For example, you need to attach them into the build system to get them up and running, and they use a custom markup language with C# embedded in them – they’re not great to work with or distribute.
At their most basic, Type Providers are themselves just F# assemblies (that anyone can write) that can be plugged into the F# compiler – and can then be used at edit-time to generate entire type systems for you to work with as you type. In a sense, Type Providers serve a similar purpose to T4 Templates, except they are much more powerful, more extensible, more lightweight to use, and are extremely flexible – they can be used with what I call “live” data sources, as well as offering a gateway not just to data sources but also to other programming languages.
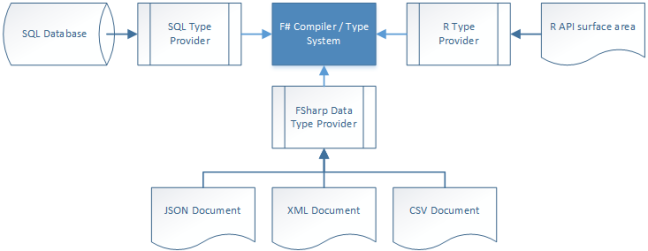
Unlike T4 Templates, Type Providers can affect type systems without re-building the project, since they run in the background as you write code. There are dozens, if not hundreds of Type Providers out there, from working with simple flat files such as CSV, to SQL, to cloud-based data storage repositories such as Microsoft Azure Storage or Amazon Web Services S3. The term “information-rich programming” refers to the concept of bringing disparate data sources into the F# programming language in an extensible way.
Don’t worry if that sounds a little confusing – we’ll take a look at our first Type Provider in just a second.
Quick Check
- What is a Type Provider?
- How do type providers differ from T4 templates?
- Is the number of type providers fixed?
Working with our first Type Provider
Let’s look at a simple example of a data access challenge – working with some soccer results, except rather than work with an in-memory dataset, we’ll work with a larger, external data source – a CSV file that you can download at https://raw.githubusercontent.com/isaacabraham/learnfsharp/master/data/FootballResults.csv. You need to answer the following question: which three teams won at home the most over the whole season.
Working with CSV files today
Let’s first think about the typical process that you might use to answer this question: –

Before we can even begin to perform the calculation, we first need to understand the data. This normally means looking at the source CSV file in something like Excel, and then designing a C# type to “match” the data in the CSV. Then, we do all of the usual boilerplate parsing – opening a handle to the file, skipping the header row, splitting on commas, pulling out the correct columns and parsing into the correct data types, etc. Only after doing all of that can you actually start to work with the data and produce something actually valuable. Most likely, you’ll use a console application to get the results, too. This process is more like typical software engineering – not a great fit when we want to explore some data quickly and easily.
Introducing FSharp.Data
We could quite happily do the above in F#; at least using the REPL affords us a more “exploratory” way of development. However, it wouldn’t remove the whole boilerplate element of parsing the file – and this is where our first Type Provider comes in – FSharp.Data.
FSharp.Data is an open source, freely distributable NuGet package which is designed to provide generated types when working with data in CSV, JSON, or XML formats. Let’s try it out with our CSV file.
Scripts for the win
At this point, I’m going to advise that you move away from heavyweight solutions and start to work exclusively with standalone scripts – this fits much better with what we’re going to be doing. You’ll notice a build.cmd file in the learnfsharp code repository (https://github.com/isaacabraham/learnfsharp). Run it – it uses Paket to download a number of NuGet packages into the packages folder, which you can reference directly from your scripts. This means we don’t need a project or solution to start coding – we can just create scripts and jump straight in. I’d recommend creating your scripts in the src/code-listings/ folder (or another folder at the same level, e.g. src/learning/) so that the package references shown in the listings here work without needing changes.
Now you try
- Create a new standalone script in Visual Studio using File -> New. You don’t need a solution here – remember that a script can work standalone.
- Save the newly created file into an appropriate location as described in “Scripts for the win”.
- Enter the following code from listing 1:
// Referencing the FSharp.Data assembly #r @"..\..\packages\FSharp.Data\lib\net40\FSharp.Data.dll" open FSharp.Data // Connecting to the CSV file to provide types based on the supplied file type Football = CsvProvider< @"..\..\data\FootballResults.csv"> // Loading in all data from the supplied CSV file let data = Football.GetSample().Rows |> Seq.toArray
That’s it. You’ve now parsed the data, converted it into a type that you can consume from F# and loaded it into memory. Don’t believe me? Check this out: –

You now have full intellisense to the dataset – that’s it! You don’t have to manually parse the data set – that’s been done for you. You also don’t need to “figure out” the types – the Type Provider will scan through the first few rows and infer the types based on the contents of the file! In effect, this means that rather than using a tool such as Excel to “understand” the data, you can now begin to use F# as a tool to both understand and explore your data.
Backtick members
You’ll see from the screenshot above, as well as from the code when you try it out yourself, that the fields listed have spaces in them! It turns out that this isn’t actually a type provider feature, but one that’s available throughout F# called backtick members. Just place a double backtick (“) at the beginning and end of the member definition and you can put spaces, numbers or other characters in the member definition. Note that Visual Studio doesn’t correctly provide intellisense for these in all cases, e.g. let-bound members on modules, but it works fine on classes and records.
Whilst we’re at it, we’ll also bring down an easy-to-use F#-friendly charting library, XPlot. This library gives us access to charts available in Google Charts as well as Plotly. We’ll use the Google Charts API here, which means adding dependencies to XPlot.GoogleCharts (which also brings down the Google.DataTable.Net.Wrapper package).
- Add references to both the GoogleCharts and Google.DataTable.Net.Wrapper assemblies. If you’re using standalone scripts, both packages will be in the packages folder after running build.cmd – just use #r to reference the assembly inside one of the lib/net folders.
- Open up the GoogleCharts namespace.
- Execute the following code to calculate the result and plot them as a chart.
data |> Seq.filter(fun row -> row.``Full Time Home Goals`` > row.``Full Time Away Goals``) |> Seq.countBy(fun row -> row.``Home Team``) |> Seq.sortByDescending snd |> Seq.take 10 |> Chart.Column |> Chart.Show // countBy generates a sequence of tuples (team vs number of wins) // Chart.Column converts the sequence of tuples into an XPlot Column Chart // Chart.Show displays the chart in a browser window

In just a few lines of code, we were able to open up a CSV file we’ve never seen, explore the schema of it, perform some operations on it, and then chart it in less than 20 lines of code – not bad! This ability to rapidly work with and explore datasets that we’ve not even seen before, whilst still allowing us to interact with the full breadth of .NET libraries that are out there gives F# unparalleled abilities for bringing in disparate data sources to full-blown applications.
Type Erasure
The vast majority of type providers fall into the category of erasing type providers. The upshot of this is that the types generated by the provider exist only at compile time. At runtime, the types are erased and usually compile down to plain objects; if you try to use reflection over them, you won’t see the fields that you get in the code editor.
One of the downsides is that this makes them extremely difficult (if not impossible) to work with in C#. On the flip side, they are extremely efficient – you can use erasing type providers to create type systems with thousands of types without any runtime overhead, since at runtime they’re just of type Object.
Generative type providers allow for run-time reflection, but are much less commonly used (and from what I understand, much harder to develop).
If you want to know more, download the free first chapter of Learn F# and see this Slideshare presentation. Don’t forget to save 37% with code fccabraham.

Promocode does not work 😦
Fixed 🙂 Sorry about that.